你是否还在为一个数据库表结构熬夜到凌晨?为一个字段类型纠结到头秃?我懂,曾经的我就是那些996的打工人,靠着无数杯咖啡,夜宵(催肥)和坚强的意志力硬撑。直到几个月前我无意中发现了——Cursor IDE + Claude Sonnet 3.5(最新3.7,它不仅仅是编码最强存在,也是视觉识别最好的模型之一),它们就像我的得力助手,让我在数据库设计领域获得了"超能力"。这套工作流不仅让我从加班地狱里解脱,还让我的设计方案质量飙升,完美融合了我们团队多年踩坑后总结的最佳实践。
看到这里,你可能会想:"又一个AI吹嘘文?"别急,这可不是纸上谈兵。我从被数据库重构项目或者新项目紧急交付数据库设计文档折磨到泪流满面,到如今的高效设计流程,是一路真刀真枪实战摸索出来的方法,绝对值得你花五分钟了解。
🔥 从"SQL手写boy"到"AI协作大师"
还记得那些日子吗?产品经理丢来一份天书般的需求文档,你盯着几十上百个业务场景,脑子里闪过无数问题:
• "这个会员等级字段,tinyint够不够?将来会不会扩展到255个以上?" • "这里的配送地址要不要设计成单独的表?" • "订单状态到底要设计几种?"
深夜十一点,你拖着疲惫的身体,一行行敲完CREATE TABLE语句,然后默默祈祷:"这设计可别有坑啊..."
而现在?Cursor+Claude组合彻底改变了游戏规则:
• 截图识别=减负神器:把产品文档、流程图、原型图直接截图丢给AI,就像有了一个24小时待命的产品经理翻译器,秒懂业务逻辑。 • 一体化环境=效率火箭:从需求理解到SQL生成,从代码审查到版本控制,全在一个工具里搞定,工作体验简直像开了"子弹时间"。
🚀 我的"AI数据库架构师"速成法
这套方法的精髓在于:用AI理解需求→用规范约束输出→通过对话优化方案→纳入版本管理。简单来说,AI是你的"高级助手",而不是替代品。
来,看看这个让我起飞的工作流:
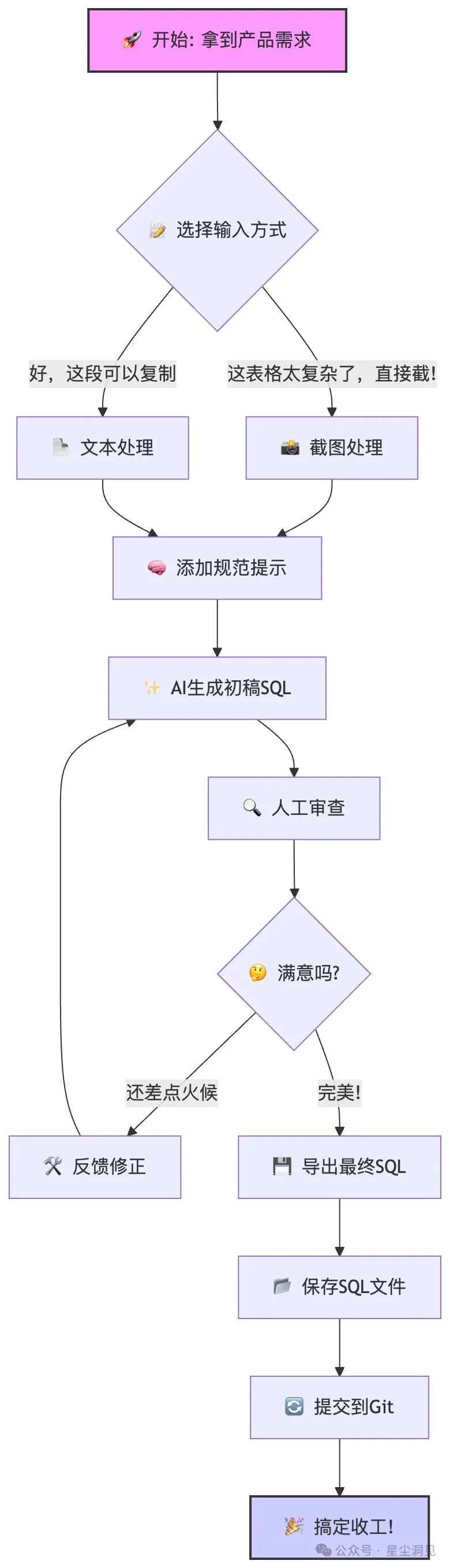
下面分享我踩过的坑和实战经验:
步骤1:需求收集——给AI喂好"原料"
就像做一道复杂的菜,原料选得好,成品才能好。这个步骤决定了整个设计的上限:
🔥 产品文档截图大法:
• 遇到复杂表格、原型图、流程图?别再手动整理了!直接截图保存。 • 实战技巧:我发现对于那些有表格结构的需求,最好同时截取表头和实例数据,这样AI能更准确推断字段类型和长度。 • 有次我遇到一个电商需求,产品文档有47页,我只用了8张关键截图,AI就准确识别出了90%以上的业务实体和关系!
💡 文本精选法:
• 对于那些格式整齐的文字需求,复制粘贴更高效。 • 实战技巧:不要全复制,只选核心业务逻辑部分,减少AI理解偏差。
步骤2:与AI的华尔兹——精准引导出完美设计
这不是简单地让AI生成SQL,而是一场精心设计的"对话舞蹈"。打开Cursor,确保用的是Claude Sonnet 3.5(3.7 更好,上下文支持更多,可以添加更多的PRD需求,帮助理解需求,更好的设计 )。
🔍 提供清晰上下文:
• 明确告诉AI这是什么类型的应用(电商、CMS、社交等)。 • 说明预估数据量和性能要求("日订单量约10万"这种信息超有用)。
📜 我的黄金提示模板:
这个提示模板是我改了20多版才定下来的,效果相当惊艳,尤其是让AI既遵循规范又保持创造性:
我有一个[应用类型]系统需求,请帮我设计最优数据库结构。
【任务说明】
分析我提供的需求(图片/文本),设计符合以下要求的数据库:
1. 提取核心业务实体与关系
2. 设计符合规范的表结构
3. 生成完整SQL
**必须遵循的数据库设计原则:**
* **命名规范**:
* 表名 `模块名_实体名` (如 `cms_article`)。
* 字段名 `snake_case`,力求**简洁、明确,避免不必要的缩写**。
* 索引名 `idx_字段名` 或 `uk_字段名` (唯一索引)。
* 表和关键字段必须有**清晰的中文注释**。
* **基础字段 (我们团队的标准)**:
* 所有表必须包含 `id` (bigint unsigned auto_increment primary key), `created_at` (datetime not null), `updated_at` (datetime not null), `deleted_at` (datetime null default null, 用于软删除)。
* 根据需要包含 `status` (tinyint not null default 1, 注释状态含义), `lang` (varchar(10) not null default 'zh-CN', 注释语言含义), `created_by` (bigint unsigned not null), `updated_by` (bigint unsigned not null)。
* **字段类型选择**:
* 优先选择最合适、最高效的类型和长度。
* 字符串:**根据预估最大长度选用 `VARCHAR(n)`,仅在必要时(如长文本内容)使用 `TEXT` 或 `LONGTEXT`**。
* 数字:整数用 `INT` 或 `BIGINT` (根据范围),**小数/金额务必使用 `DECIMAL(m,n)`**。
* 时间:时间戳用 `DATETIME`,若只需日期用 `DATE`。
* 布尔值/简单枚举:使用 `TINYINT`,并在注释中说明含义 (例如 `COMMENT '状态 (0:禁用, 1:启用)'`)。
* **枚举/状态处理**:
* **简单、固定枚举 (如状态)**: 使用 `TINYINT` 并加注释说明。
* **(备选方案)** 对于复杂、可能变化或需后台管理的枚举值,可考虑设计专门的**字典表 (Dictionary Table)** 模式,但这非本模板默认要求。
* **索引设计**:
* 主键自带索引。
* 为所有**经常用于查询条件 (WHERE)、排序 (ORDER BY)、分组 (GROUP BY) 的字段或字段组合**创建索引 (`INDEX idx_...`)。
* 为需要保证**唯一性的字段或字段组合**创建 `UNIQUE KEY uk_...`。
* 遵循最左前缀原则设计复合索引。
* **避免过度索引**,权衡查询性能提升与写入性能损耗。
* **其他重要规范**:
* 存储引擎统一使用 `InnoDB`。
* 字符集统一使用 `utf8mb4`,排序规则 `utf8mb4_unicode_ci`。
* **严格禁止在数据库层面使用外键约束 (FOREIGN KEY)**,关联逻辑在应用层保证。
* 为字段设置**合理且明确的 `DEFAULT` 值** (如 `0`, `''`, `'默认值'`, `CURRENT_TIMESTAMP`),或显式允许 `NULL` ( `DEFAULT NULL`)。
**请严格按照以下 SQL 模板生成 `CREATE TABLE` 语句(业务字段需根据 PRD 智能填充):**
-- 示例模板,仅供参考结构,具体字段需智能生成
DROP TABLE IF EXISTS `模块名_表名`;
CREATE TABLE `模块名_表名` (
`id` bigint UNSIGNED NOT NULL AUTO_INCREMENT COMMENT '主键ID',
-- === 业务字段 (请根据PRD智能填充) ===
`title` VARCHAR(255) NOT NULL COMMENT '标题示例 (使用VARCHAR)',
`content` TEXT NULL COMMENT '内容示例 (必要时使用TEXT)',
`price` DECIMAL(10, 2) NOT NULL DEFAULT 0.00 COMMENT '价格示例 (使用DECIMAL)',
`user_email` VARCHAR(128) NULL COMMENT '用户邮箱 (可能需要唯一索引)',
-- === 标准字段 (按需添加) ===
`status` tinyint NOT NULL DEFAULT 1 COMMENT '状态 (0:禁用, 1:启用)',
`created_at` datetime NOT NULL COMMENT '创建时间',
`updated_at` datetime NOT NULL COMMENT '更新时间',
`deleted_at` datetime NULL DEFAULT NULL COMMENT '删除时间 (软删除标记)',
`created_by` bigint UNSIGNED NOT NULL COMMENT '创建人用户ID',
`updated_by` bigint UNSIGNED NOT NULL COMMENT '最后更新人用户ID',
PRIMARY KEY (`id`) USING BTREE,
-- === 常用索引 (按需添加) ===
INDEX `idx_status` (`status`) USING BTREE,
-- === 其他业务索引 (请根据PRD智能添加) ===
INDEX `idx_created_at` (`created_at`) USING BTREE,
UNIQUE KEY `uk_user_email` (`user_email`) USING BTREE, -- 唯一索引示例
-- INDEX `idx_combo_example` (`field_a`, `field_b`) USING BTREE -- 复合索引示例
) ENGINE = InnoDB CHARACTER SET = utf8mb4 COLLATE = utf8mb4_unicode_ci COMMENT '表说明 (请根据PRD智能生成)';
请将所有表的 SQL 语句统一完整输出,不要中途省略或分开输出。💡 建议:将上述SQL模板保存为
sql_template.md文件,修改符合你业务的内容,方便日后快速引用和使用
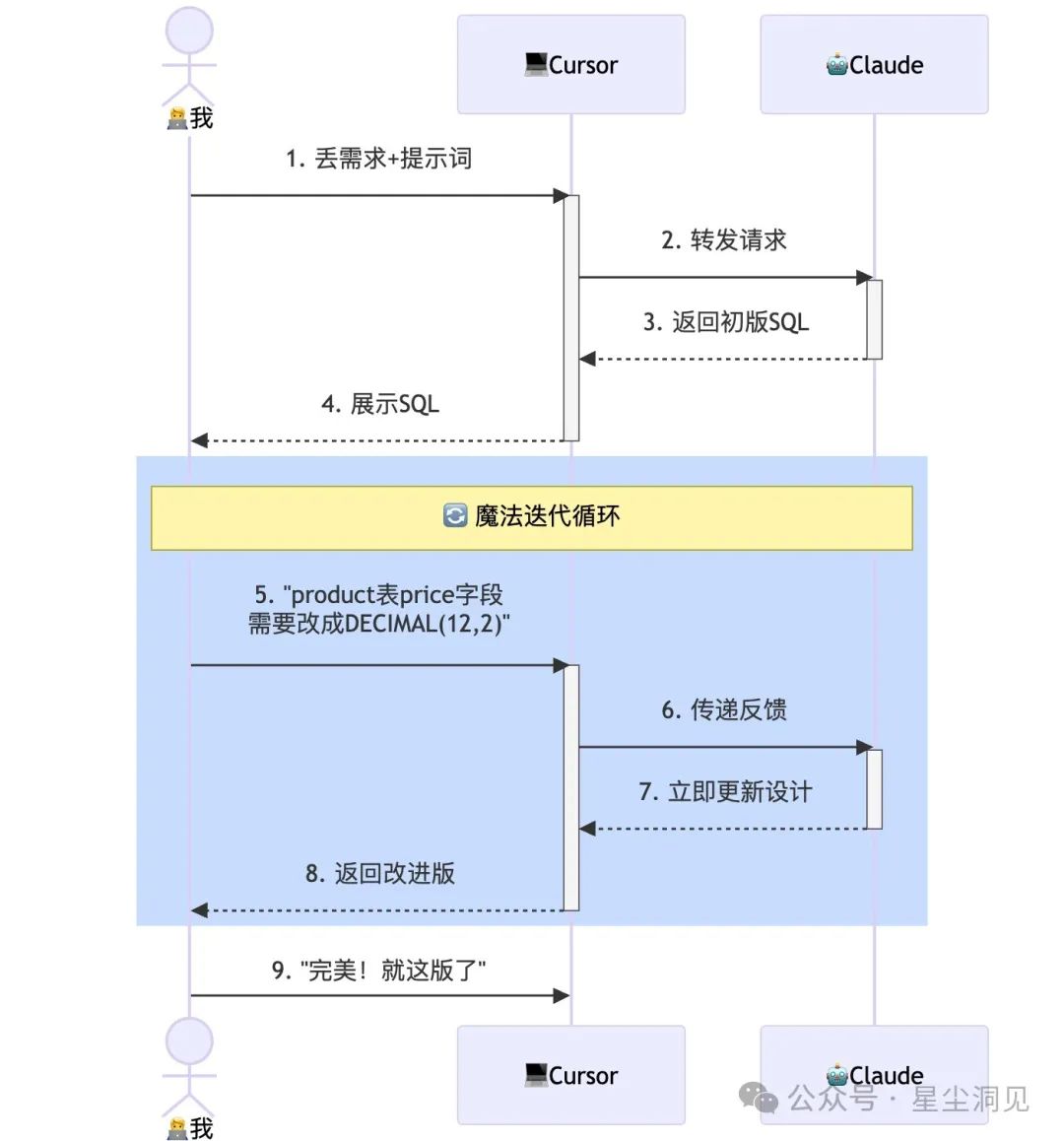
步骤3:AI+人类的"最强协作"——迭代优化到完美
这可能是最神奇的步骤——AI给出初稿后,你的反馈会让它迅速进化。就像调教一个天才学徒,几轮对话后,你会惊讶于结果的质量:
我的亲身经历:上周有个电商平台数据库,初版AI设计了18张表,通过5轮对话,我们不仅优化了字段类型,还发现并解决了两个潜在的设计缺陷(多语言支持的问题)。这在传统方式下可能要等到开发中期才能暴露出来!
💎 审查必查清单:
• 需求覆盖:所有业务场景都能支持吗? • 规范遵循:命名、类型、注释都符合团队标准吗? • 扩展性:未来可能的业务变化能平滑支持吗? • 性能考量:大数据量下会有瓶颈吗?索引设计合理吗?
🔧 反馈小技巧:
你可以直接用Prompt告诉AI需要修改什么,就像和同事沟通一样:
"user表需要增加mobile字段,varchar(20),加唯一索引"
"订单状态太简单了,应该设计为:0未支付、1已支付待发货、2已发货待收货、3已完成、4已取消、5已退款"
"comment表content字段应该用TEXT类型,VARCHAR(255)太小了"
步骤4:从SQL到版本库——让成果永续流传
当方案达到完美状态,是时候把它纳入项目正式资产了:
1. 导出整理:复制最终SQL,我通常会加上详细注释说明设计思路。 2. 创建迁移文件:在Cursor中创建migration文件(如 migrations/202307121_create_ecommerce_tables.sql)。3. 提交版本:Git提交时写明详细说明,方便后续查阅("feat(db): 新增电商核心表结构设计")。 4. 引用复用:后续开发中,用 @migrations/xxx.sql引用,AI能读懂这些表结构,协助开发CRUD代码。也可以用Cursor 生成对应的Model 代码,可以引入对应的生成模版加上数据库SQL 生成Model 文件。具体使用方式你可以参考往期的文章中有介绍,不再追溯。
🎯 真实案例:一个完整的表设计"蜕变"过程
分享一个真实案例:我们接到一个社区电商小程序项目,需要设计数据库。以往这种项目数据库设计至少需要1-2天,而现在整个过程缩短到了不到2小时!
⚡ 初始设计
把产品文档截图和PRD文本丢给AI后,它给出了初版表设计,包含8张基础表:
-- 用户表 CREATE TABLE `user_member` ( `id` bigint UNSIGNED NOT NULL AUTO_INCREMENT COMMENT '用户ID', `nickname` varchar(50) NOT NULL DEFAULT '' COMMENT '用户昵称', `avatar` varchar(255) NOT NULL DEFAULT '' COMMENT '头像URL', -- 其他字段... ) COMMENT='用户基本信息表'; -- 其他表...🔄 问题发现与改进
审查过程中,我们发现了几个问题:
1. 问题:用户手机号没有唯一索引
反馈:"用户表需要给mobile字段添加唯一索引"
AI更新:立即添加了UNIQUE KEY uk_mobile (mobile)2. 问题:订单状态设计过于简单
反馈:"订单状态需要更详细,应包括待付款、已付款待发货、已发货待收货、已完成、已取消、已退款六种状态"
AI更新:修改了状态定义并更新了注释3. 问题:缺少社区团购的核心表设计
反馈:"需要增加团长表和团购活动表的设计"
AI更新:增加了两张表并设计了合理的字段和关联关系
✨ 最终收获
经过约5轮迭代,我们得到了一套完整的、符合业务需求的数据库设计,包含12张表的完整SQL。更棒的是,这套设计已经投入生产环境3个月,至今没有因设计缺陷而修改表结构!
额外惊喜:因为有了这套完整的表结构定义,后续让AI生成的CRUD代码质量也大幅提升,代码生成准确率从之前的60%提高到了90%以上!
🔮 为什么这套方法"真香"?
当我向团队其他成员分享这套方法时,最初有怀疑,但尝试后都成了"真香警告"的传播者。为什么呢?
• 告别重复劳动:表设计有大量模式化工作,现在可以集中精力在真正需要创造力的部分。 • 降低认知负担:不用再同时记忆十几个设计规范点,AI会帮你检查。 • 提升设计质量:多轮审查机制显著减少设计缺陷,减少后期修改成本。 • 促进知识沉淀:设计规范和经验可以编码到提示词中,新人也能快速产出高质量方案。 • 全流程加速:从需求理解到代码生成,整个过程无缝衔接,效率提升不止一点点。