确保你已经安装了以下库:
pandas:用于数据处理。
openpyxl:用于读写Excel文件。
numpy:用于数值计算。
matplotlib 和 seaborn:用于数据可视化。
你可以使用以下命令安装这些库:
pip install pandas openpyxl numpy matplotlib seaborn脚本列表
读取Excel文件
写入Excel文件
筛选特定列
筛选特定行
删除空值
填充空值
重命名列
计算总和
计算平均值
计算最大值
计算最小值
计算标准差
计算百分比变化
计算累计和
计算同比增长
计算环比增长
数据透视表
合并多个Excel文件
拆分Excel文件
格式化日期
按日期排序
按多个列排序
分组求和
分组计数
分组平均值
条件筛选
条件替换
添加新列
删除列
删除行
查找重复值
删除重复值
数据归一化
数据标准化
绘制折线图
绘制柱状图
绘制饼图
绘制箱线图
绘制散点图
绘制热力图
计算复利
计算现值
计算未来值
计算内部收益率(IRR)
计算净现值(NPV)
计算投资回报率(ROI)
计算年化收益率
计算资产负债表比率
计算利润表比率
计算现金流量表比率financial_data.xlsx 数据示例
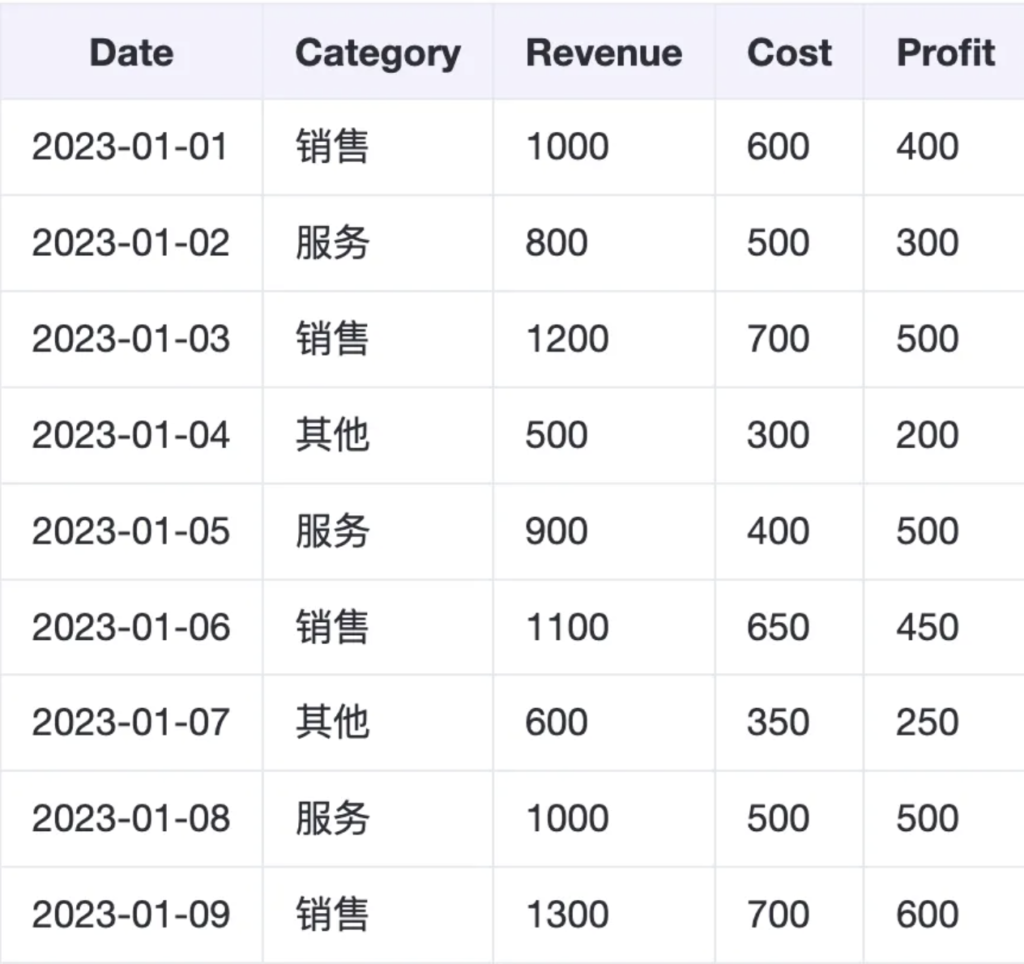
假设我们有一个简单的财务数据表,包含以下列:
Date:日期
Category:类别(例如:销售、服务、其他)
Revenue:收入
Cost:成本
Profit:利润(收入 - 成本)
示例数据
创建 financial_data.xlsx 文件
你可以使用以下Python代码创建并保存这个Excel文件:
import pandas as pd
from datetime import datetime, timedelta
# 创建示例数据
data = {
'Date': [datetime(2023, 1, 1) + timedelta(days=i) for i in range(10)],
'Category': ['销售', '服务', '销售', '其他', '服务', '销售', '其他', '服务', '销售', '其他'],
'Revenue': [1000, 800, 1200, 500, 900, 1100, 600, 1000, 1300, 700],
'Cost': [600, 500, 700, 300, 400, 650, 350, 500, 700, 400],
'Profit': [400, 300, 500, 200, 500, 450, 250, 500, 600, 300]
}
# 创建DataFrame
df = pd.DataFrame(data)
# 保存为Excel文件
df.to_excel('financial_data.xlsx', index=False)
print("financial_data.xlsx 已创建")运行上述代码
运行上述代码后,会在当前目录下生成一个名为 financial_data.xlsx 的Excel文件,其中包含示例数据。
1. 读取Excel文件
import pandas as pd
# 读取Excel文件
df = pd.read_excel('financial_data.xlsx')
print(df)2. 写入Excel文件
import pandas as pd
# 创建一个DataFrame
data = {'Date': ['2023-01-01', '2023-01-02', '2023-01-03'],
'Revenue': [100, 150, 200]}
df = pd.DataFrame(data)
# 写入Excel文件
df.to_excel('output.xlsx', index=False)3. 筛选特定列
import pandas as pd
# 读取Excel文件
df = pd.read_excel('financial_data.xlsx')
# 筛选特定列
selected_columns = df[['Date', 'Revenue']]
print(selected_columns)4. 筛选特定行
import pandas as pd
# 读取Excel文件
df = pd.read_excel('financial_data.xlsx')
# 筛选特定行
filtered_rows = df[df['Revenue'] > 100]
print(filtered_rows)5. 删除空值
import pandas as pd
# 读取Excel文件
df = pd.read_excel('financial_data.xlsx')
# 删除包含空值的行
df_cleaned = df.dropna()
print(df_cleaned)6. 填充空值
import pandas as pd
# 读取Excel文件
df = pd.read_excel('financial_data.xlsx')
# 填充空值
df_filled = df.fillna(0)
print(df_filled)7. 重命名列
import pandas as pd
# 读取Excel文件
df = pd.read_excel('financial_data.xlsx')
# 重命名列
df_renamed = df.rename(columns={'OldName': 'NewName'})
print(df_renamed)
8. 计算总和
import pandas as pd
# 读取Excel文件
df = pd.read_excel('financial_data.xlsx')
# 计算总和
total = df['Revenue'].sum()
print(f'Total Revenue: {total}')9. 计算平均值
import pandas as pd
# 读取Excel文件
df = pd.read_excel('financial_data.xlsx')
# 计算平均值
average = df['Revenue'].mean()
print(f'Average Revenue: {average}')10. 计算最大值
import pandas as pd
# 读取Excel文件
df = pd.read_excel('financial_data.xlsx')
# 计算最大值
max_value = df['Revenue'].max()
print(f'Max Revenue: {max_value}')11. 计算最小值
import pandas as pd
# 读取Excel文件
df = pd.read_excel('financial_data.xlsx')
# 计算最小值
min_value = df['Revenue'].min()
print(f'Min Revenue: {min_value}')12. 计算标准差
import pandas as pd
# 读取Excel文件
df = pd.read_excel('financial_data.xlsx')
# 计算标准差
std_dev = df['Revenue'].std()
print(f'Standard Deviation of Revenue: {std_dev}')13. 计算百分比变化
import pandas as pd
# 读取Excel文件
df = pd.read_excel('financial_data.xlsx')
# 计算百分比变化
df['Pct_Change'] = df['Revenue'].pct_change()
print(df)14. 计算累计和
import pandas as pd
# 读取Excel文件
df = pd.read_excel('financial_data.xlsx')
# 计算累计和
df['Cumulative_Sum'] = df['Revenue'].cumsum()
print(df)15. 计算同比增长
import pandas as pd
# 读取Excel文件
df = pd.read_excel('financial_data.xlsx')
# 计算同比增长
df['YoY_Growth'] = df['Revenue'].pct_change(periods=12) * 100
print(df)16. 计算环比增长
import pandas as pd
# 读取Excel文件
df = pd.read_excel('financial_data.xlsx')
# 计算环比增长
df['MoM_Growth'] = df['Revenue'].pct_change() * 100
print(df)17. 数据透视表
import pandas as pd
# 读取Excel文件
df = pd.read_excel('financial_data.xlsx')
# 创建数据透视表
pivot_table = pd.pivot_table(df, values='Revenue', index='Category', aggfunc='sum')
print(pivot_table)18. 合并多个Excel文件
import pandas as pd
import glob
# 获取所有Excel文件
files = glob.glob('*.xlsx')
# 读取并合并所有Excel文件
all_data = pd.concat([pd.read_excel(file) for file in files], ignore_index=True)
print(all_data)19. 拆分Excel文件
import pandas as pd
# 读取Excel文件
df = pd.read_excel('financial_data.xlsx')
# 按类别拆分
for category, group in df.groupby('Category'):
group.to_excel(f'{category}.xlsx', index=False)20. 格式化日期
import pandas as pd
# 读取Excel文件
df = pd.read_excel('financial_data.xlsx')
# 将日期列转换为日期时间格式
df['Date'] = pd.to_datetime(df['Date'])
print(df)